pedro
a. ramírez
*makes projects,
commissions,
releases,
graphics,
text and
code.
*about
*calendar
*links:
︎ bandcamp
︎ nina

Speech Bubbles & Bespoke Chatter (2023)




The sound installation deconstructs the mechanisms of computer-based voice recognition based on the model of the technical exploded view. The capture, decomposition and manipulation of linguistic utterances in the pre-semantic phase opens up various possibilities for perceiving people beyond the voice mediated by algorithms.
With the rise of Artificial Intelligence, interest in machine listening as a method for real-time word discretisation (the process of transferring continuous variables into discrete counterparts) and recognition is also growing. Available applications now range from OpenAI's Whisper, which can convert unintelligible mumbling into individual words, to Siri, Alexa and countless other services that operate in bidirectional routings between speech and text.
What kinds of algorithms are inscribed in these tools? What aesthetic potential do they have as instruments for expanding the musical toolbox of a contemporary sound artist? How can we find new ways of understanding the substance of our language through the spectral differentiation of sound events? How does our desire transform into words, words into air and then into bits? This work looks at alternative aesthetic approaches to those technologies commonly associated with the ever-listening apparatuses of contemporary Big Tech.
The work is interested in the concept of exploded representation in technical drawings; schematics in which the various elements of a functioning machine are depicted in order to explain its inner workings. The sound installation similarly explodes the mechanisms of voice recognition by looking at them in a pre-semantic phase and trying to show different ways in which the sound images of humans can be perceived in the digital. The focus is not on the semantics of the words, but on the extraction of features to reveal the extraordinary in the smooth processes of speech recognition algorithms.
Exhibition view at Ephemeral Connections, 2024
Technical description:![]()
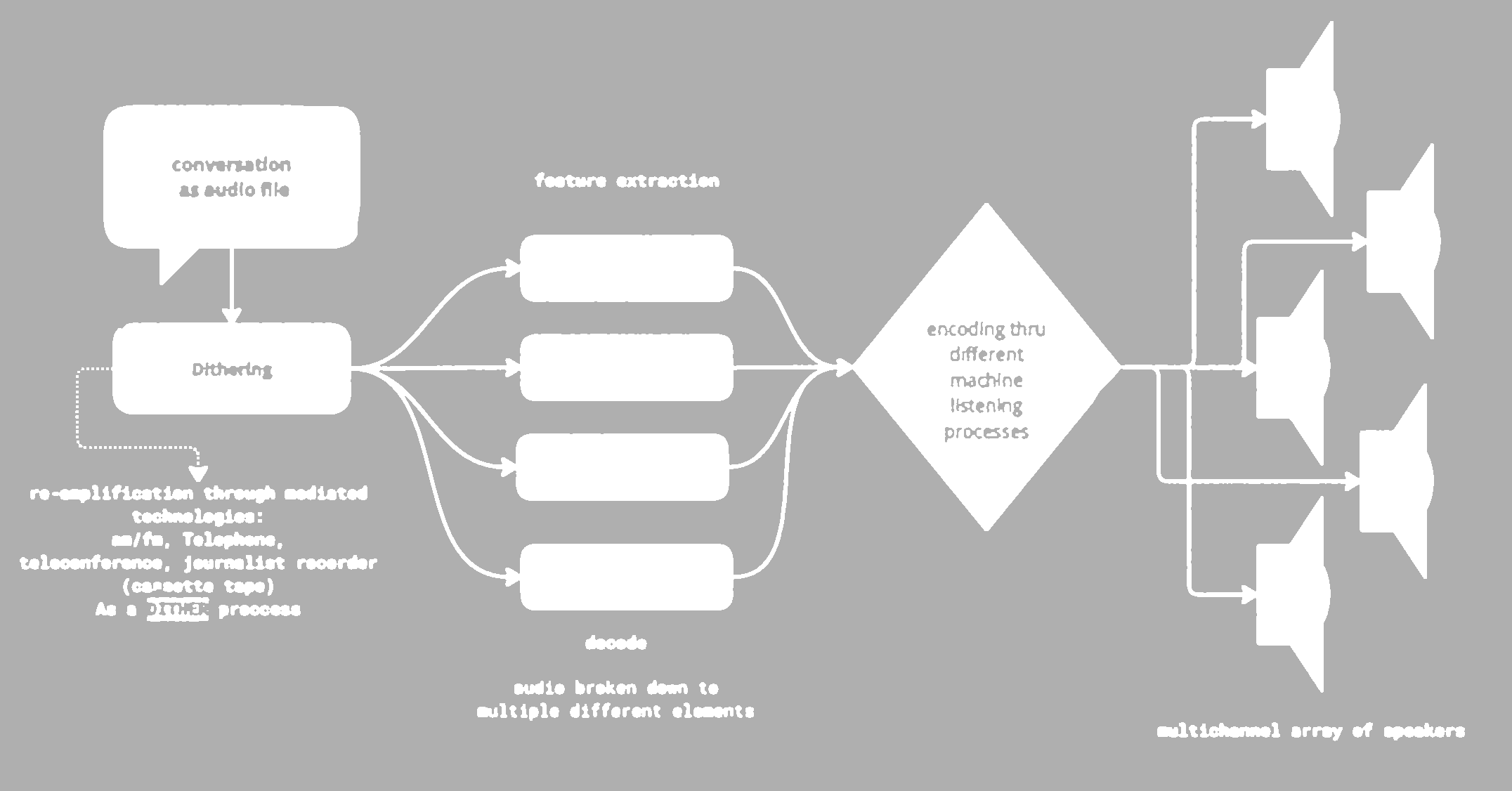

Personal voice messages are digitalized and preamplified through several voice recording technologies (journalist cassette recording, smartphone microphone, telephone amplifiers) and then analyzed and broken apart by machine listening algorithms (Flucoma, Supercollider ML Ugens).
The results of this atomization are then taken raw and diffused in the exhibition space through the usage of rotating directional ultrasonic speakers. Because of the stark directionality of the speakers, the sound is heard not in the speaker itself but in the reflection of the sound beam in the room, creating the impression of digital sound objects traversing and moving in the exhibition space.
Exhibited in:
- Kölner Kongress 2024. Erzählen gegen die Krise @ Deutschlandradio Funkhaus (info here)